







[问题描述]
教科书第10章中,介绍了多种排序算法,并从理论角度对各种算法的时间复杂度进行了分析。依据书中的理论知识,设计一个排序算法比较程序,试比较几种内部排序算法的关键字比较次数和移动次数(关键字交换视为3次移动),以得到对各种排序算法执行效率的直观感受。
[基本要求]
(1)以顺序表作为待排序表的存储结构,其中表长(即关键字个数)不小于100,表中数据随机产生,至少用5组不同数据作比较。
(2)至少实现起泡排序(Bubble)、直接插入排序(Insert)、简单选择排序(Select)、快速排序(Quick)、希尔排序(Shell)、堆排序(Heap)几种基本排序算法。
(3)输出比较结果。分别输出采用各种排序算法对每组数据进行排序前的待排序序列和排序后的排序结果序列;分别输出对应5组数据,各类算法比较的结果表
***线性表结构****
typedef struct
{
ElemType *elem; //存储空间基址
int length; //当前长度
int listsize; //当前分配的存储空间容量(以sizeof(ElemType)为单位)
}SqList;
【分析】
分析每个排序算法在那个位置是在进行位置移动,哪些地方在进行数据比较;比如拿最简单冒泡为例:
//起泡排序(Bubble)
void Bubble(SqList &L)
{
compare=0,move=0;
int i,j,t;
for(j=0;j<L.length-1;j++)
for(i=0;i<L.length-1-j;i++)
{ compare++;
if(L.elem[i]>L.elem[i+1])
{t=L.elem[i];L.elem[i]=L.elem[i+1];L.elem[i+1]=t;move++;}
}
}int compare=0,move=0; 记录比较次数和移动次数
其中两个for循环就是在比较知道比较到了if(L.elem[i]>L.elem[i+1])这句,循环一次compare加一知道条件满足就能进行交换,交换一次move加一。就这样把这组数据排序的比较次数和移动次数都记录出来了。
用了一个简单计数法用compare和move分别记录比较次数和移动次数。
其他排序算法大家照教材一一分析。。。。。。。。
直接插入排序(Insert)
void Insert(SqList &L)
{
int i,j;
for(i=2;i<L.length;++i)
{
compare++;
if(L.elem[i]<L.elem[i-1])
{
L.elem[0]=L.elem[i];
L.elem[i]=L.elem[i-1];
for(j=i-2;L.elem[i]<L.elem[i-1];--j)
{
L.elem[j+1]=L.elem[j];
move++;
compare++;
}
L.elem[j+1]=L.elem[0];
move+=3;
}
}
}
简单选择排序(Select)
/***简单选择***/
//简单选择排序(Select)
void Select(SqList &L)
{
compare=0,move=0;
int i=0,j=0,t=0;
for(i=1;i<=L.length;i++)//选择第i小的记录,并交换到位
{
j=SelectMin(L,i);//在 L.elem[i....L.lengh]中选择key最小的记录
if(i!=j)//与第i个记录交换
{move++; t=L.elem[i];L.elem[i]=L.elem[j];L.elem[j]=t;}//互换
}
}
int SelectMin(SqList &L,int i)//选取最小
{
int j=1,k=1;
for(j=i;j<=L.length;j++)
{compare++; if(L.elem[j]<=L.elem[i]) k=j;}
return k;
}
/***简单选择结束***/
快速排序(Quick)
/*****快速排序****/
//快速排序(Quick)
void Quick(SqList &L,int low,int high)
{
int pivot=0;
if(low<high)//长度大于1
{
pivot=QsortPartion(L,low,high);//将L.elem[low...high]一分为二
Quick(L,low,pivot-1);//对低子表递归排序,pivot是枢轴位置
Quick(L,pivot+1,high);//对高子表递归排序
}
}
void QuickSort(SqList &L)//快速排序
{
Quick(L,1,L.length);
}
int QsortPartion(SqList &L,int low,int high)//快速排序子函数
{
int key=0;
key=L.elem[low];//枢轴记录关键字
move++;
while(low<high)//从表的两端交替地向中间扫描
{
compare+=2;
while(low<high&&L.elem[high]>=key) --high;
L.elem[low]=L.elem[high];//将比枢轴记录小的记录移动到低端
move++;
while(low<high&&L.elem[low]<=key) ++low;
L.elem[high]=L.elem[low];//将比枢轴记录大的记录移动到高端
move++;
}
L.elem[low]=key;//枢轴记录到位
move++;
return low;//返回枢轴位置
}
/****快速排序结束***/
希尔排序(Shell)
/****希尔排序****/
//希尔排序(Shell)
void Shell(SqList &L,int dk )//对顺序表L做一趟希尔插入排序
{
int j;
for(int i=dk+1;i<=L.length;i++)
{
compare++;
if(L.elem[i]<L.elem[i-dk])//需将L.elem[i]插入到有序增量子表
{
L.elem[0]=L.elem[i];//暂存在L.elem[0]
move++;
for( j=i-dk;j>0&&(L.elem[0]<L.elem[j]);j-=dk)
{
L.elem[j+dk]=L.elem[j];//记录后移,查找插入位置
move++;
compare++;
}
L.elem[j+dk]=L.elem[0];//插入
move++;
}
}
}
void Shellsort(SqList &L,int dlta[],int t)//按增量序列dlta[0...t-1]对顺序表L做希尔排序
{
int k;
compare=0,move=0;
for(k=0;k<t;k++)
Shell(L,dlta[k]);//一趟增量为dlta[k]的插入排序
}
/****希尔排序结束****/
堆排序(Heap)
void Heap(SqList &L)//堆排序
{
int i=1,t;
compare=0,move=0;
for(i=L.length/2;i>0;i--)
HeapAdjust(L,i,L.length);
for(i=L.length;i>1;i--)
{
move++;
{t=L.elem[1];L.elem[1]=L.elem[i];L.elem[i]=t;}
HeapAdjust(L,1,i-1);
}
}
void HeapAdjust(SqList &L,int s,int m)//建堆函数
{
int j,rc;
rc=L.elem[s];
for(j=2*s;j<=m;j*=2)//沿key较小的孩子结点向下筛选
{
compare+=2;
if(j<m&&(L.elem[j]<L.elem[j+1])) ++j; //j为key较小的记录的下标
if(!(rc<L.elem[j])) break;// 堆调整结束
L.elem[s]=L.elem[j]; s=j;//较小的孩子结点值换到父结点位置
move++;
}
L.elem[s]=rc;//rc应插入的位置在s处
move++;
}
/****堆排序结束****/
主要排序算法都给出,其他大家自行设计编写。按照顺序表基本操作实现数据输入和输出。
主函数:
void main()
{
int i,j;
int dlta[3]={5,3,1},t=3;//希尔函数增量数组
SqList L1;
printf("-----|---------------比较次数------------------||---------------移动次数------------------|\n");
printf(" 分组|Bubble|Insert|Select|Quick |Shell | Heap ||Bubble|Insert|Select|Quick |Shell | Heap |\n");
for(j=0;j<5;j++)
{
InitList_Sq(L1);
for(i = 1; i <=100; i++)
{
L1.elem[i]=rand()%100;
ListInsert_Sq(L1,i,L1.elem[i]);
}
printf("\n");
Bubble(L1);
Insert(L1);
Select(L1);
QuickSort(L1);
Shellsort(L1,dlta,t);
Heap(L1);
printf(" %d | %d | %d | %d | %d | %d | %d || %d | %d | %d | %d | %d | %d |\n",
j+1,compare1,compare2,compare3,compare4,compare5,compare6,move1,move2,move3,move4,move5,move6);
}
}
最后科普随机数表示
主要函数 rand()
(1) 如果你只要产生随机数而不需要设定范围的话,你只要用rand()就可以了:rand()会返回一随机数值, 范围在0至RAND_MAX 间。RAND_MAX定义在stdlib.h, 其值为2147483647。
例如:
#include<stdio.h>
#include<stdlib.h>
void main()
{
for(int i=0;i<10;i+)
printf("%d/n",rand());
}
(2) 如果你要随机生成一个在一定范围的数,你可以在宏定义中定义一个random(int number)函数,然后在main()里面直接调用random()函数:
例如:随机生成10个0~100的数:
#include<stdio.h>
#include<stdlib.h>
#define random(x) (rand()%x)
void main()
{
for(int x=0;x<10;x++)
printf("%d/n",random(100));
}
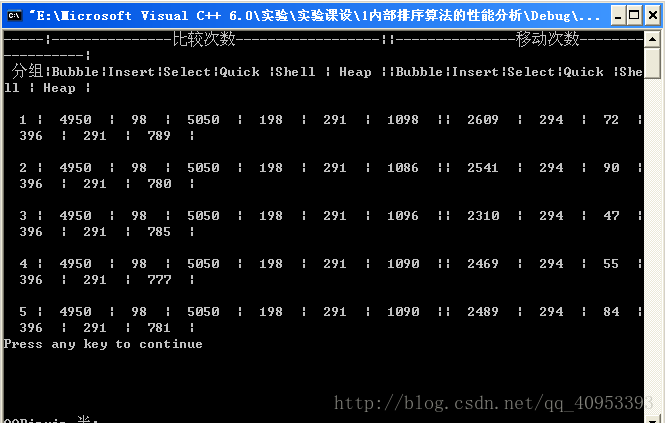
结果展示:(格式没调好,出来不美观,窗口宽度有限)
















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











